
Transport is a key part of most people’s day and so it inevitably ends up in the news. Much of this news appears in local papers, which make up the majority of the 700+ news outlets in the UK. For some policymakers, these news stories are a useful and informal input to the policy development process.
As human readers who understand how the English language works and what the Department for Transport (DfT) does, we can quickly identify if a piece of news is relevant to our policymakers. Yet, despite our suitability to the task, there is simply too much news generated each day to keep up with. This got the Data Science team thinking: could we teach a computer to do this for us?
The problem with keywords
A common approach to solving this is to come up with a list of keywords you’re interested in and search the news media each day for articles that contain these words. But as these news results with the word ‘car’ in the headline show, this approach quickly runs into problems:
“Pranksters put HALF a Mini car at top of the 'Nuneaton nipple' - but why?”
Coventry Live
“Drivers are angry at queues of 'more than two hours' to get out of St David's car park in Cardiff”
Wales Online
“Highly charged: complaints as electric car points block city pavements”
The Guardian

The Nuneaton Nipple source. The UK’s No. 1 Landmark
What has been placed atop the ‘Nuneaton nipple’ is probably of little interest to colleagues at DfT, but the other 2 articles may be of interest. So to refine the results, we need to use keywords in a smarter way.
One way could be to write more complex rules to filter the news. For example, the Plug-in Vehicle Infrastructure team could receive articles that contain the words ‘car’ and ‘electric’ or ‘car’ and ‘charging’. But this doesn’t get to the root of the issue - there are a vast amount of niche topics that different teams are interested in, and manually programing the right filters would be a mammoth task. Plus, the programmers don’t have the subject matter expertise to come up with sensible filters.
Our solution is to outsource the subject expertise to the teams themselves. This gives them an easy way to train the computer to know which articles are relevant today, based on what was relevant in the past. And using machine learning algorithms to transfer the heavy processing to the computer.
The prototype
Our current prototype addresses the core problem. We used 300 articles that we already knew were relevant to aviation policy to teach the model to identify new aviation articles correctly.
Computers aren’t equipped to deal with language, but they can process increasingly vast amounts of numbers. To convert text into something a computer can digest we convert sentences into a matrix of word counts, referred to as a ‘bag of words’. If we do this for a selection of the words featured in the car headline results, we can begin to spot patterns in the data. For example, the Guardian article headline features the words ‘car’ and ‘electric’ but not ‘park’ or ‘queues’.
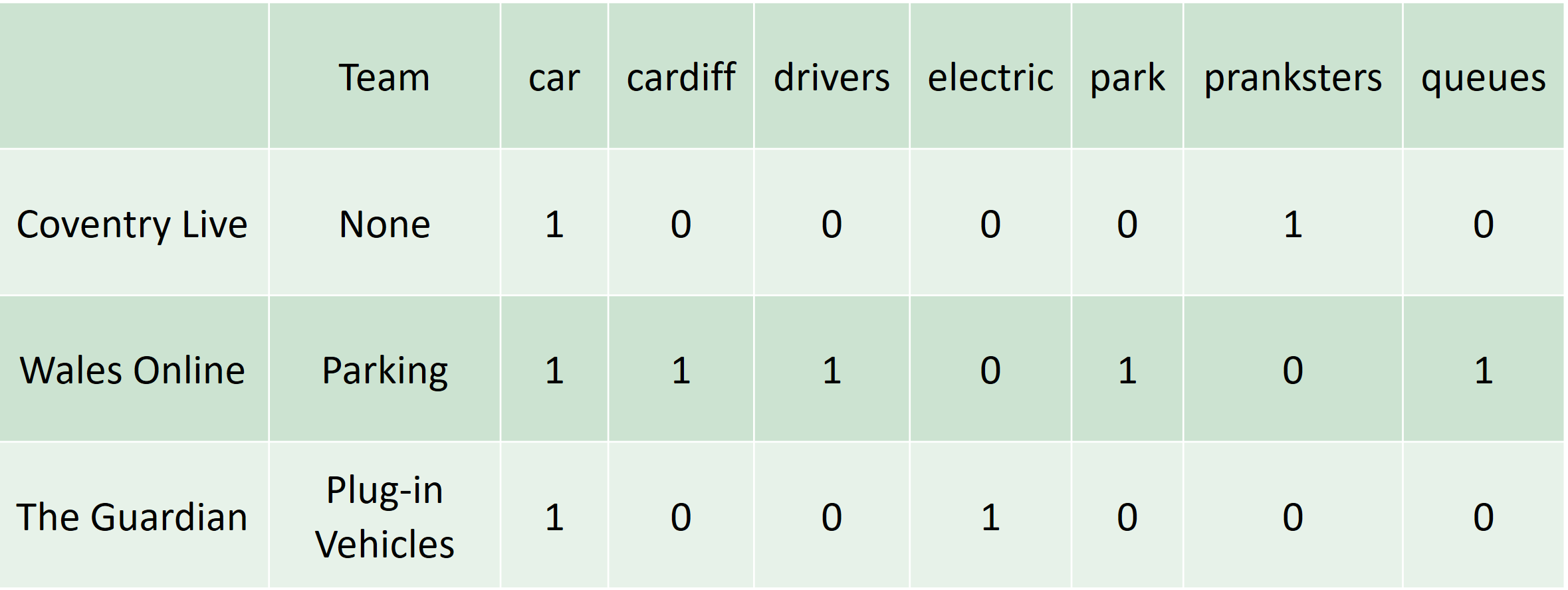
If we have a selection of articles that we know are of interest to a particular team, we can use the word counts of these articles to train a model, such as a Naive Bayes classifier (PDF 326KB), to make predictions.
Without going into detail, the process involves calculating the probability that a word, for example ‘park’ will appear in documents we’ve tagged as belonging to a team. And using those probabilities, it can calculate the most likely category for new documents. We can see from the word counts table the probability that articles with the word ‘park’ belong to the Parking category is much higher than the probability for the word ‘electric’. In reality, we apply this process to thousands of words and hundreds of articles.
Once the model has identified relevant articles, we use natural language processing to select the most important keywords from the article and the most important sentence. We include this in a daily email and send it to the relevant team. In this way, we hope the recipient gets a summary of what the article is about without having to open the link (just in case the headline is not accurate).
In the long term, we want to make the tool self-sufficient, by allowing recipients to improve the predictions with each email by voting whether the selected article was relevant or not. Doing so will provide the model with more data which in turn will improve the accuracy of predictions.
Get in touch
We are also exploring other ways we can use this data - at present we have 40,000 articles that contain transport related keywords. If this project is of interest to you - or you’re interested in other text processing get in touch at Data.Science@dft.gov.uk
1 comment
Comment by Alex posted on
Brilliant! I can see immediate parallels with correspondence sorting, and indeed, the same teams receiving your (media) output will probably be dealing with the sharp end of queries about correspondence... a ready made user group.