The Department for Transport receives around 70,000 bits of correspondence a year of various types, usually requiring a response. Examples include questions from MPs and emails or letters from the public. We’re very good at answering them but we wanted to know if we could improve the process.
Let’s say each bit takes ten minutes to log, draft a response, and get out the door, that’s about 12,000 hours a year. And that’s a conservative estimate.
DfT invests in being accountable, open and accessible and we take pride in answering correspondence as promptly as possible. But could we do even better by making smarter use of technology? That’s what the DfT Lab set out to investigate – could we develop a system to improve our performance and reduce the time and cost? We started out by designing a basic working piece of software to do this, called a prototype.
Finding pain points
We spoke to the team in the Minister’s office who process correspondence coming in to the Department, the prospective users of our prototype, to decide what problems to focus our attention on. From our discussion, 2 key issues came out.
The first was in transposing data (name, address, etc) from a scanned bit of mail to a database. This takes time and can easily introduce errors.
The second problem is that it’s hard to know who to allocate each bit of correspondence to. This can be a challenge because:
- people change jobs
- some correspondence needs answers from a number of different teams
- sometimes letters are about unusual topics that are difficult to plac
Solution Part 1 – Extracting data
So we have our problem, but what’s the solution? We think it’s machine learning. Machine learning is a kind of artificial intelligence and involves setting the parameters of a problem, and letting the computer figure out how to do it.
The first problem is quite easy to solve. We fed our scanned images to the Google Cloud Vision API. This recognises the text and converts it into a digital form which is readable by other programs. For the protoype we made up a set of test data with publicly available names, addresses, emails etc(ie from the Parliament website). For the finished article we would need of course to assess how securely sensitive data could be stored.
We then used something called the Stanford Named Entity Recognizer, which is brilliant at identifying people’s names, to capture who it’s from and who it’s to. Then we used some regular expressions to capture dates, email addresses and reference numbers.
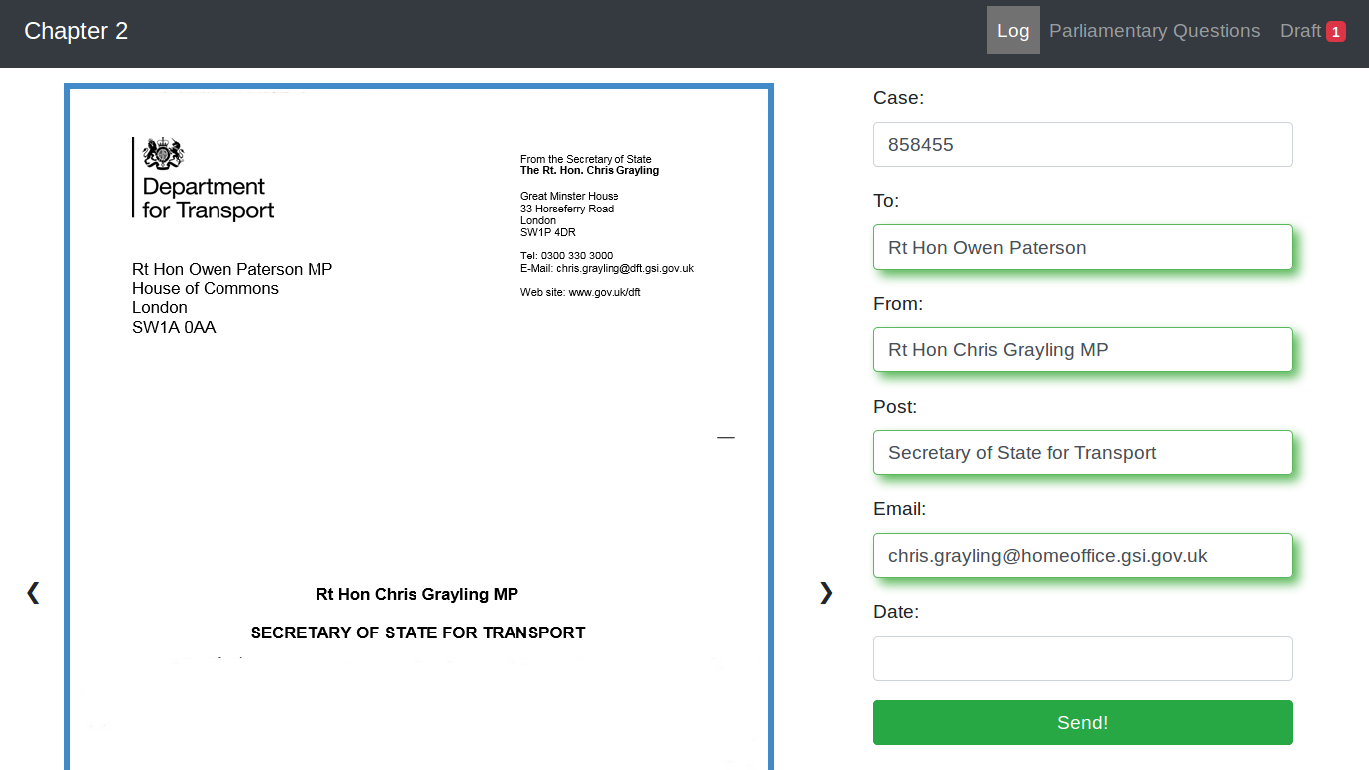
As you can see in this dummy example, it’s automatically filled in the required fields, as well as pulling information about the sender’s job from Parliament’s API, saving time and reducing errors.
Solution Part 2 – Sorting correspondence
For the second problem, we wanted to train the machine to know which team in the department should answer each letter.
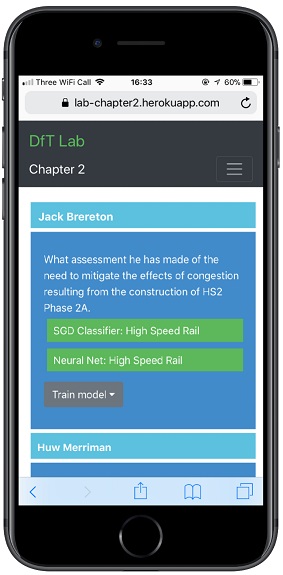
To begin with, we focused on parliamentary questions (PQs) because they’re quite short and already available in a digital format. We used about 5,000 of them to train a neural network to recognise PQs and allocate them correctly.
A neural network is a simple model of the human brain: a network of switches that fire depending on the intensity of their input. We train this network by inputting our PQs, and the computer tweaks the sensitivity of our switches to get the right result consistently. It’s a cool name for a deceptively simple concept.
In practice, we don’t need to know too much about how the neural net arranges itself, we just need to know if it works! And after some head scratching it did, with about 90% accuracy.
You can play with some of our models yourself at: https://lab-chapter2.herokuapp.com (It’ll be quite slow to load though!)
What’s next
While 90% accuracy is pretty good for a proof of concept, it’s probably not good enough for an actual product, so needed to train the machine further in order to make it really useful.
We focused on PQs, as the data was easy to get hold of, and with some small(ish) tweaks, our models could reliably sort all the correspondence the department gets.
Right now, our machine sorts into teams, which is easy compared to the real requirement – routing the correspondence to the right person for drafting – and that’s where our current models fall down. Machine learning relies on big data sets to train, with thousands and thousands of entries. Most of us respond to less than 10 bits of correspondence a year.
I’m confident that, with a bit of data massaging, we could improve our accuracy and match PQs with people, but that’s a problem for another time (though I’m all ears if you’ve got any ideas!).
So that’s it, prototype complete! Now we’re working with the private office correspondence team to explore how we could take some of the technology forward. The real world will present a whole lot of challenges we didn’t have to navigate, so watch this space!
And finally...
Finally, it was news to me, but according to the government’s independent review ‘Growing the artificial intelligence industry in the UK’:
“The government will need to ensure that staff have the skills and practical tools needed to recognise and realise how AI can help them deliver their responsibilities and objectives”
It’s ambitious, but true. Machine learning isn’t just for academics or Google - it’s a tool for everyone. And it doesn’t have to be complicated.
So if you want some help thinking about how your team might use machine learning, or any technology, the Lab wants to help. So drop us a line – lab@dft.gsi.gov.uk
We will also be posting regularly here about what we’ve cooked up in DfT Labs. Please sign up for alerts to be notified.
5 comments
Comment by Roger Witte posted on
The sentence "In practice, we don’t need to know too much about how the neural net arranges itself, we just need to know if it works!" is only true up to a point. If you cannot explain what the neural net is doing then you should have some kind of feedback loop so that it can continue to learn while it is in use. The problem is that the way people use language is evolves over time (its a fashion thing) and you either need to be able to spot when to adjust your algorithm (from understanding how it behaves) or to have it update itself . Actually the automated feedback is probably the better of my two suggestions
Comment by Zach posted on
Hey Roger, yep good point
One thing we would've liked to have done (had we the time) is to complete that feedback loop, i.e have the user override/confirm predictions, store that data and then retrain the model(s) regularly
Comment by Brad Smith posted on
Hi - read with interest.
I infer the big time saver will be allocating questions to people to draft responses - can you query your PQ database and see which individual got similar responses allocated to them in the past and send it to them in first instance, with a feedback loop for them to update your neural net if the machine got it wrong?
Comment by Zach posted on
Hey Brad,
Yep good idea, would've been good to try that out, though i suspect we'd still need more data.
One thing that might be cool is using people's staff directory data (which includes skills, memberships and stuff) to match with PQs (or indeed any question!). Maybe next time.....
Comment by Brad Smith posted on
Also a good idea - but that depends on that being kept up-to-date - maybe staff directories could be updated with people's skills based on output from questions answered too?
Keep up the good work 🙂